VectorDB tool
VectorDB is a robust tool enabling you to generate embeddings for your content, such as websites or extended texts, and store them in your dedicated VectorDB. Once stored, SWE facilitates the retrieval of data from these embeddings, allowing your application's model to utilize it for additional context. Currently, SWE offers support for pgvector (PostgreSQL) and Pinecone. Learn more about the tool concept here
Pay attention
Please note that to achieve this successfully, you must use the same embedding model in SWE that you used to store the data.
PostgreSQL limitations
- Password limitations: Please note that passwords should not contain the characters
@and:. If your password includes these characters, you will need to modify them in your connection string as follows:
- Replace
@with%40. For example:dialect://admin:My%[email protected]/dbtest- Replace
:with%3A. For example:dialect://admin:My%[email protected]/dbtest- Table schema limitation: Please ensure that all column names are in lowercase with no capital letters.
Pinecone End-to-End Example
For your convenience, we provide a comprehensive end-to-end example in a Google Colab notebook for using Pinecone. This example covers everything from creating the index to setting up the vector database tool on our platform. Enjoy!
PGvector Prerequisite: Setting up vectorDB for Superwise integration
Before you begin, ensure your database meets the following requirements:
When connecting Postgres vectorDB to the Superwise application, the following tables are required in the database:
langchain_pg_collection
This table is used to save all the collections of documents (referred to as a "table" in the Superwise platform).
DDL:
CREATE TABLE public.langchain_pg_collection (
name varchar NULL,
cmetadata json NULL,
uuid uuid NOT NULL,
CONSTRAINT langchain_pg_collection_pkey PRIMARY KEY (uuid)
);
Columns explanation:
- name: The name of the collection (this is the table_name when creating the tool).
- cmetadata: Metadata for the collection.
- uuid: The ID of the collection.
langchain_pg_embedding
This table is connected to the langchain_pg_collection table and stores documents along with their embeddings.
DDL:
CREATE TABLE public.langchain_pg_embedding (
collection_id uuid NULL,
embedding public.vector NULL,
document varchar NULL,
cmetadata json NULL,
custom_id varchar NULL,
uuid uuid NOT NULL,
CONSTRAINT langchain_pg_embedding_pkey PRIMARY KEY (uuid)
);
ALTER TABLE public.langchain_pg_embedding
ADD CONSTRAINT langchain_pg_embedding_collection_id_fkey
FOREIGN KEY (collection_id)
REFERENCES public.langchain_pg_collection(uuid)
ON DELETE CASCADE;
Columns explanation:
- collection_id: The ID of the collection the document is connected to.
- document: The text document.
- embedding: Embedding of the document.
- cmetadata: Metadata for the embedding (to enable cite sources, it should contain the source information like this: {"source": "https://js.langchain.com/docs/modules/memory").
- custom_id: User-defined custom ID.
- uuid: The ID of the document embedding.
Using the UI
This guide will walk you through creating a VectorDB tool using the user interface (UI) client. VectorDB tools help connect your system to a database containing vector embeddings, which can be used to enrich prompts and improve model understanding.
- Add a New Tool:
- Click the "+ Tool" button. This opens a menu where you can choose the type of tool you want to add.
- Select "VectorDB tool" to begin setting up the connection.
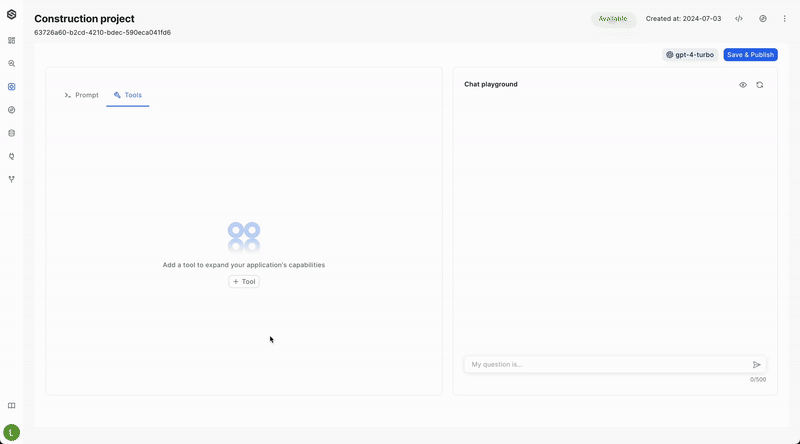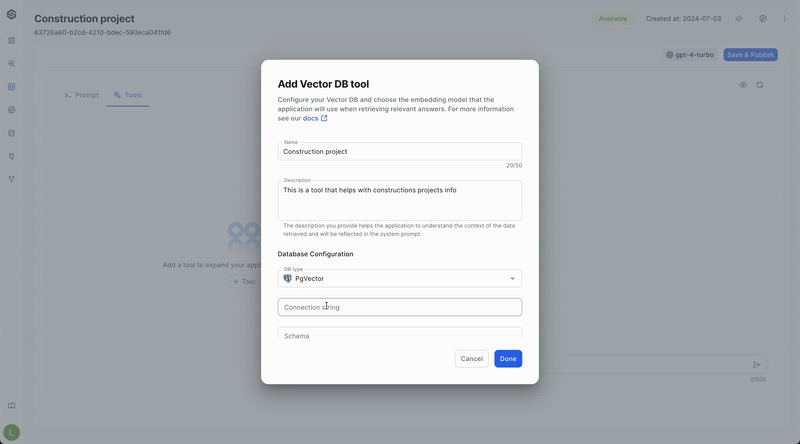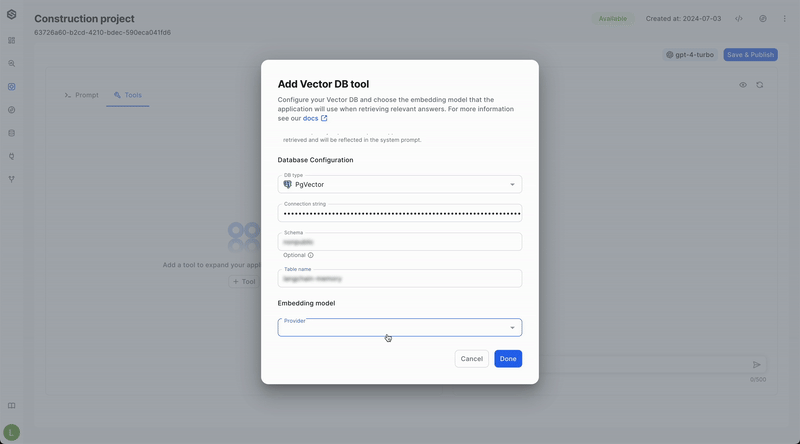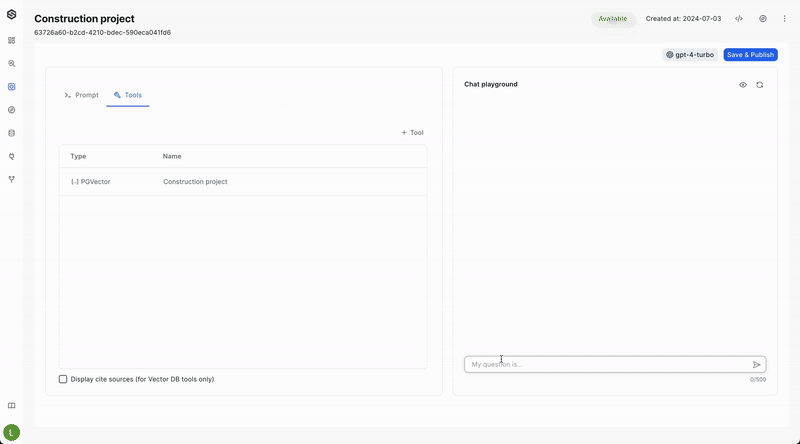
- Name Your Tool: Assign a descriptive name to your tool. This helps the model understand the context in which the data will be used. For example, "Product Embeddings" or "Customer Search Vectors" would be good choices.
- Describe Your tool: Consider adding a comprehensive description of your tool. This helps the model understand the purpose and context of your database. Explain what kind of data the embeddings represent (e.g., product descriptions, user profiles) and how they are used in your system. This information can improve the relevance and accuracy of the prompts generated by the model
- Choose the VectorDB Type: This refers to the specific type of database technology used for your VectorDB. If you're unsure, consult your system administrator.
- Connect to Your Database: Enter the necessary connection details to connect to your VectorDB instance. The required details vary depending on the specific VectorDB you are using:
- Pgvector:
- Provide the connection string in the following format:
postgresql://username:password@host:port/database - Enter schema name (Optional)
- Enter the table name
- Provide the connection string in the following format:
- Pinecone:
- Enter your Pinecone API key
- Provide the Index name
- Pgvector:
- Link your embedding model : Provide information about the specific model here. Please pay attention that to achieve this successfully, you must use the same embedding model in SWE that you used to store the data.
By following these steps, you'll successfully set up a VectorDB tool within the UI. This will allow your system to leverage the power of vector embeddings, potentially leading to improved performance and more insightful results.
Using the SDK
To begin crafting your VectorDB tool with the help of the SDK, you'll find the provided code snippets below as an invaluable guide. These snippets will lead you through the necessary steps to integrating the VectorDB tool into your workflow
Step 1: Create embedding model
OpenAI embedding model
from superwise_api.models.tool.tool import OpenAIEmbeddingModel, EmbeddingModelProvider, OpenAIEmbeddingModelVersion
openai_embedding_model=OpenAIEmbeddingModel(
provider=EmbeddingModelProvider.OPEN_AI,
version=OpenAIEmbeddingModelVersion.TEXT_EMBEDDING_ADA_002,
api_key="Your API key"
)
Google Vertex AI Model Garden embedding model
from superwise_api.models.tool.tool import EmbeddingModelProvider, VertexAIModelGardenEmbeddingModel
vertex_embedding_model=VertexAIModelGardenEmbeddingModel(
provider=EmbeddingModelProvider.VERTEX_AI_MODEL_GARDEN,
project_id="Your project id",
endpoint_id="Your endpint id",
location="us-central1",
service_account={SERVICE_ACCOUNT}
)
Step 2: Create tool
Tool creation includes the following details:
- Assign a meaningful name to your tool. The chosen name will aid the model in recognizing the context for which the data is intended.
- Connect to Your Database: Enter the necessary connection details to connect to your VectorDB instance. The required details vary depending on the specific VectorDB you are using:
- Pgvector:Provide the connection string in the following format:
postgresql://username:password@host:port/database, Schema name (optional) and table name - Pinecone: Enter your Pinecone API key and Provide the Index name
- Pgvector:Provide the connection string in the following format:
- Provide a comprehensive description of the tool. Elaborate on the database’s purpose and its operational context. This description helps the model to contextualize the data, thereby enhancing the relevance and accuracy of the system-generated prompts
- Link your embedding model : Provide information about the specific model here. Please pay attention that to achieve this successfully, you must use the same embedding model in SWE that you used to store the data.
Pgvector code example:
from superwise_api.models.application.application import AdvancedAgentConfig
from superwise_api.models.tool.tool import ToolDef, ToolType, \
ToolConfigPGVector, EmbeddingModelProvider, \
VertexAIModelGardenEmbeddingModel
vectordb_tool =ToolDef(
name="Tool name",
description="Describe this tool for the LLM",
config=ToolConfigPGVector(
type=ToolType.PG_VECTOR,
connection_string="CONNECTION_STRING",
table_name="Your table name",
db_schema="Your schema name",
embedding_model=openai_embedding_model
)
)
updated_app = sw.application.put(str(app.id),
llm_model=model,
prompt=None,
additional_config=AdvancedAgentConfig(tools=[vectordb_tool]),
name="My application name",
show_cites=True
)
Pinecone code example:
from superwise_api.models.tool.tool import ToolDef, ToolType, ToolConfigPineconeVectorDB
vectordb_tool =ToolDef(
name="Tool name",
description="Describe this tool for the LLM",
config=ToolConfigPineconeVectorDB(
type=ToolType.PINECONE,
api_key="Your pinecone key",
index_name="Your index name",
embedding_model=openai_embedding_model
)
)
updated_app = sw.application.put(str(app.id),
llm_model=model,
prompt=None,
additional_config=AdvancedAgentConfig(tools=[vectordb_tool]),
name="My application name",
show_cites=True
)
Test connection
SWE offers you the option to check the connection to your resources in any given time by using the following API call
Test connection to pgvector
POST app.superwise.ai/v1/applications/test-tool-connection
{
"type": "PGVector",
"connection_string": "",
"table_name": "",
"embedding_model": {
"provider": "VertexAIModelGarden",
"project_id": "",
"location": "",
"endpoint_id": "",
"service_account": {
"type": "service_account",
"project_id": "",
"private_key_id": "",
"private_key":"",
"client_email": "",
"client_id": "",
"auth_uri": "",
"token_uri": "",
"auth_provider_x509_cert_url": "",
"client_x509_cert_url":"",
"universe_domain":""
}
}
}
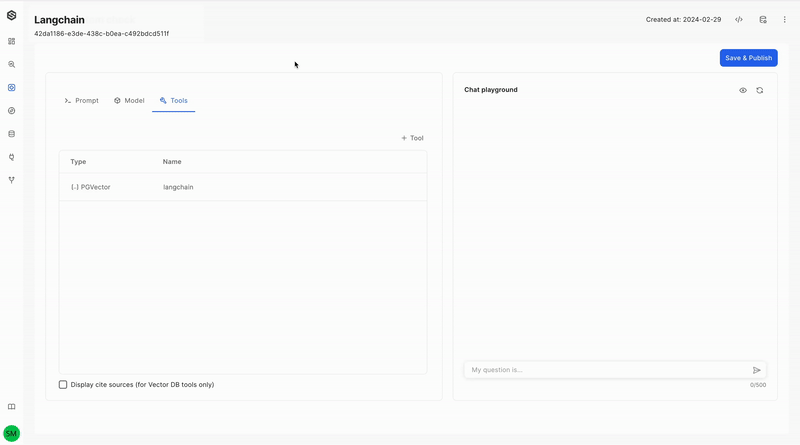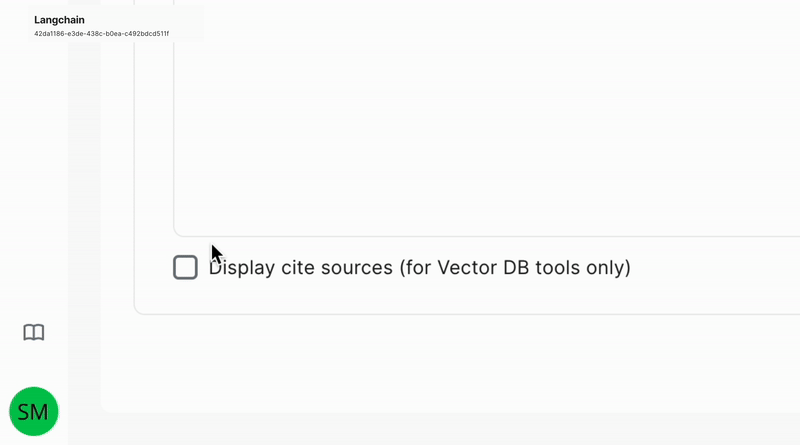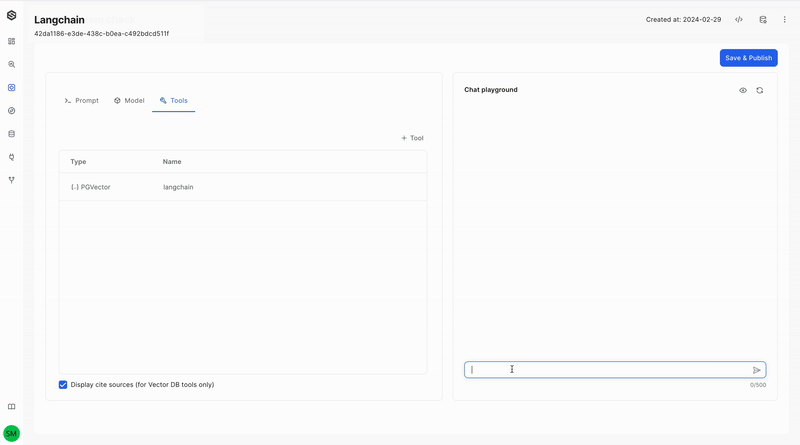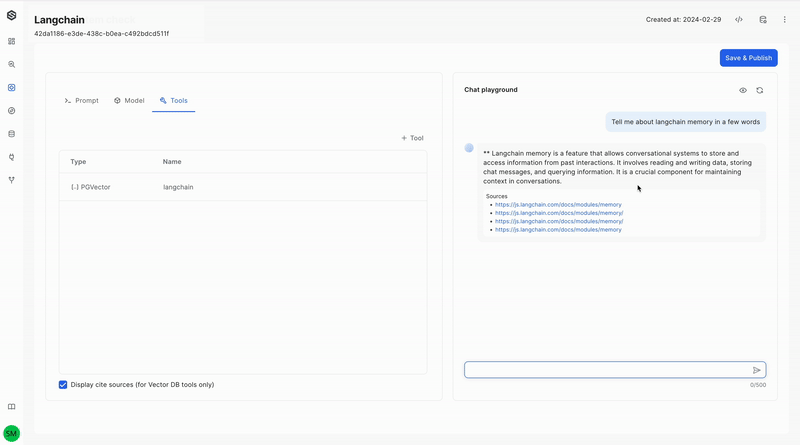
Cite Sources
SWE now provides the capability to view the sources behind the model’s responses, enhancing transparency and traceability in your data analysis. By citing sources, you can delve deeper into the origin of the data that influenced the model's decisions.
Important notice
The cite sources feature is available exclusively for VectorDB tools.
How to enable source citing in pgvector
To leverage this feature, you must first ensure that your data is indexed correctly in VectorDB. Detailed below are the steps necessary to index your data for source citation:
Create a Document Store and Send to a Vector Database with pgvector
A step-by-step guide on how to embed text stores and send them to a vector database using pgvector. pgvector is an extension for PostgreSQL that allows the storage of high-dimensional vectors, enabling efficient similarity search and machine learning applications.
Prerequisites
Before you begin, ensure you have the following:
- PostgreSQL installed (version 13 or later is recommended).
- pgvector extension installed.
- Python environment with necessary libraries installed (such as psycopg2) for PostgreSQL connection and a vector embedding library (like transformers, or openai for built-in text embedding models).
Installation
- Install Necessary Libraries: In this example, we will use the out-of-the-box model embedding options provided by OpenAI. We will need the following libraries and packages:
!pip install langchain-openai langchain langchain-community pgvector
import os, json, openai
from langchain_community.vectorstores import PGVector
from langchain_community.document_loaders import DirectoryLoader
from langchain_core.embeddings import Embeddings
from langchain.schema.document import Document
from typing import List
from openai import OpenAI
- Load OpenAI API Key to Environment: We will also need an OpenAI API key for adding our embeddings to pgvector:
os.environ["OPENAI_API_KEY"] = KEY_STRING
Steps to Embed Text and Store in Vector Database
- Set PostgreSQL Connection String: Based on the credentials of your PostgreSQL vector database and the requirements for PostgreSQL secure database connections URLs, we can create a connection string, such as in this format:
conn_string = postgresql+psycopg2://{USER}:{PASSWORD}@{HOST}:{PORT}/{DB_NAME} - Assign Collection Name for Storing Vectors: Next, we want to create a new collection name, which will be assigned to a corresponding collection id in the langchain_pg_collection table. This id will be used to identify the embeddings for our new collection in the lanchain_pg_embeddings table.
collection_name = “documentation_tutorial” - Define Embedding Model: We can leverage one of OpenAI’s embedding models by defining a simple embedding class, as shown below:
client = OpenAI()
class OpenAIEmbeddings(Embeddings):
def **init**(self, openai_api_key: str):
self.api_key = openai_api_key
openai.api_key = self.api_key
def embed_query(self, text: str) -> List[float]:
return self.embed_documents([text])[0]
def embed_documents(self, texts: List[str]) -> List[List[float]]:
embeddings = []
for text in texts:
embedding = client.embeddings.create(input = [text], model="text-embedding-3-small").data[0].embedding
embeddings.append(embedding)
return embeddings
embedding_model = OpenAIEmbeddings(openai_api_key=os.getenv("OPENAI_API_KEY"))
In this example, we are leveraging the “text-embedding-3-small” model for our embeddings. Note that, when we connect a Superwise application to this vector DB destination, we will need to assign an embedding model with the same embedding dimensionality as “text-embedding-3-small”. This embedding model will allow us to interface with our new vector DB collection in the application’s agent system.
- Convert Text to Langchain Documents and Add Source Metadata: We can specify a file directory of text files, each of which will be loaded as its own document, through langchain’s DirectoryLoader:
loader = DirectoryLoader(file_path, glob="\*.txt")
documents = loader.load()
Note that chunking large text corpora into smaller documents can be achieved by leveraging one of langchain’s Text Splitters.
Upon inspecting each document, we can see that, by default, the “metadata” field is populated with a document source, which corresponds to the full file path: metadata={'source': '/sample_text_docs/doc_one.txt'})
Manual metadata configurations may be implemented iteratively across a full list of texts (in this example, document_store). We can align our metadata fields to the cmetadata fields in our default langchain_pg_embeddings table:
documents = []
for text_doc in document_store:
documents.append(Document(page_content = text_doc,
metadata = {"source": new_source,
"title": new_title,
"description": "",
"language": "en"
}
)
- Send Documents to PostgreSQL Vector Database: Finally, we can use the PGVector class from LangChain to create a vector store from a list of documents. The vector store is stored in a PostgreSQL database using the pgvector extension:
vectorstore = PGVector.from_documents(
embedding=embedding_model,
documents=documents,
collection_name=collection_name,
connection_string=conn_string,)
- Querying the Vector Database: To retrieve text entries, we can use vector queries on our newly created vector collection. Here’s an example:
conn = psycopg2.connect(conn_string)
cur = conn.cursor()
query = f"SELECT \* FROM langchain_pg_embedding e INNER JOIN langchain_pg_collection c ON e.collection_id = c.uuid WHERE c.name = "{collection_name}"
cur.execute(query)
rows = cur.fetchall()
pd.DataFrame(rows, columns = ["name", "cmetadata", "uuid"])
Note that, in this case, the connection string should assume the Keyword/Value Connection String format.
By following this guide, you can successfully embed text data, store it in a PostgreSQL database using the pgvector extension, and perform efficient similarity searches. This process enables powerful text processing and machine learning applications directly within your PostgreSQL database.
For further customization and optimization, refer to the documentation for pgvector and langchain.
By following these steps, you'll be able to make full use of the cite sources feature in SWE, gaining deeper insights and confidence in the model’s responses
Enabling Cite Sources in the UI
After indexing the data and its sources as mentioned above, simply enable the "Display Cite Sources" option in the Tools tab of your application. This will allow you to view the sources for the model’s responses, enhancing the transparency of your data analysis.
Updated 3 months ago