VectorDB context
VectorDB enables you to generate embeddings for your content, such as websites or extended texts, and store them in your dedicated VectorDB. Once stored, SWE facilitates the retrieval of data from these embeddings, allowing your application's model to utilize it for additional context. Currently, SWE offers support for pgvector (PostgreSQL) and Pinecone. Learn more about the tool concept here
Pay attention
Please note that to achieve this successfully, you must use the same embedding model in SWE that you used to store the data.
PostgreSQL limitations
- Password limitations: Please note that passwords should not contain the characters
@and:. If your password includes these characters, you will need to modify them in your connection string as follows:
- Replace
@with%40. For example:dialect://admin:My%[email protected]/dbtest- Replace
:with%3A. For example:dialect://admin:My%[email protected]/dbtest- Table schema limitation: Please ensure that all column names are in lowercase with no capital letters.
PGvector Prerequisite: Setting up vectorDB for Superwise integration
Before you begin, ensure your database meets the following requirements:
When connecting Postgres vectorDB to the Superwise application, the following tables are required in the database:
langchain_pg_collection
This table is used to save all the collections of documents (referred to as a "table" in the Superwise platform).
DDL:
CREATE TABLE public.langchain_pg_collection (
name varchar NULL,
cmetadata json NULL,
uuid uuid NOT NULL,
CONSTRAINT langchain_pg_collection_pkey PRIMARY KEY (uuid)
);
Columns explanation:
- name: The name of the collection (this is the table_name when creating the tool).
- cmetadata: Metadata for the collection.
- uuid: The ID of the collection.
langchain_pg_embedding
This table is connected to the langchain_pg_collection table and stores documents along with their embeddings.
DDL:
CREATE TABLE public.langchain_pg_embedding (
collection_id uuid NULL,
embedding public.vector NULL,
document varchar NULL,
cmetadata json NULL,
custom_id varchar NULL,
uuid uuid NOT NULL,
CONSTRAINT langchain_pg_embedding_pkey PRIMARY KEY (uuid)
);
ALTER TABLE public.langchain_pg_embedding
ADD CONSTRAINT langchain_pg_embedding_collection_id_fkey
FOREIGN KEY (collection_id)
REFERENCES public.langchain_pg_collection(uuid)
ON DELETE CASCADE;
Columns explanation:
- collection_id: The ID of the collection the document is connected to.
- document: The text document.
- embedding: Embedding of the document.
- cmetadata: Metadata for the embedding (to enable cite sources, it should contain the source information like this: {"source": "https://js.langchain.com/docs/modules/memory").
- custom_id: User-defined custom ID.
- uuid: The ID of the document embedding.
Using the UI
This guide will walk you through creating a VectorDB context using the user interface client. VectorDB context help connect your system to a database containing vector embeddings, which can be used to enrich prompts and improve model understanding.
- Add a New Context:
- Click the "+ context" button. This opens a menu where you can choose the type of context you want to add.
- Select "VectorDB" to begin setting up the connection.
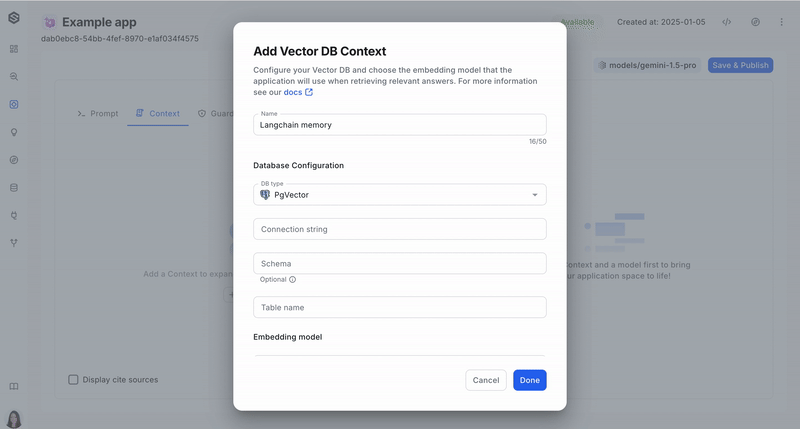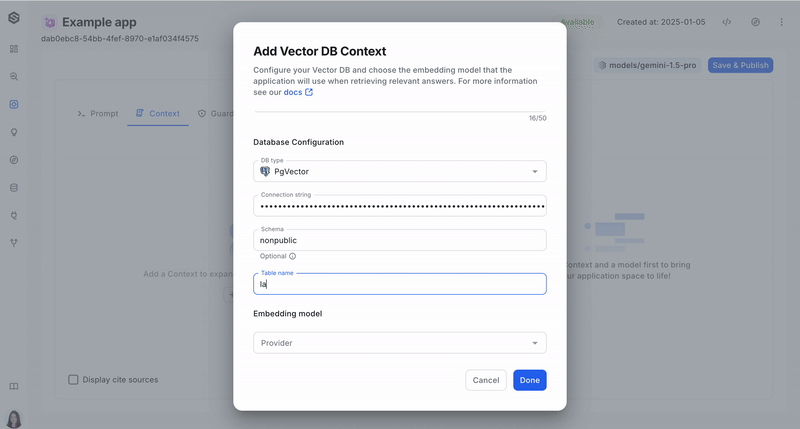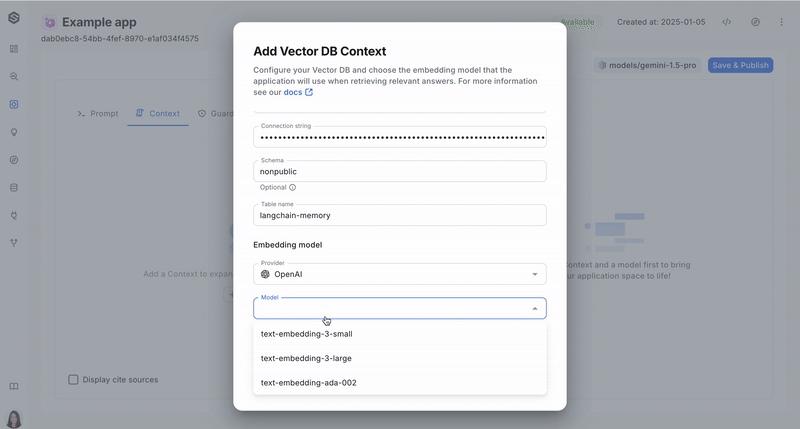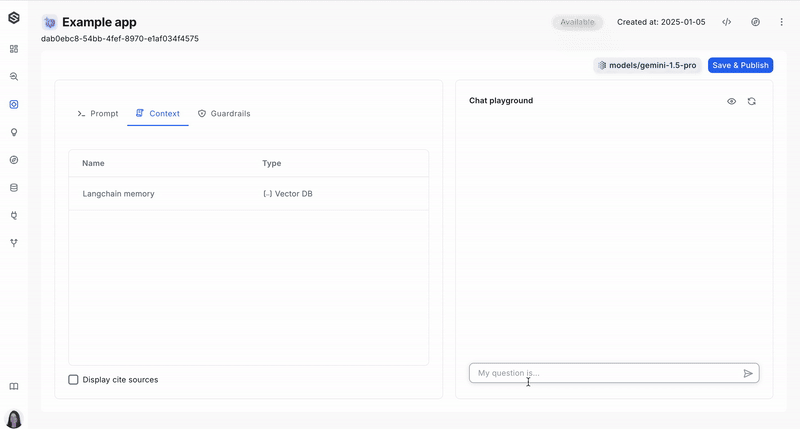
- Name Your context: Assign a descriptive name to your context.
- Choose the VectorDB Type: This refers to the specific type of database technology used for your VectorDB. If you're unsure, consult your system administrator.
- Connect to Your Database: Enter the necessary connection details to connect to your VectorDB instance. The required details vary depending on the specific VectorDB you are using:
- Pgvector:
- Provide the connection string in the following format:
postgresql://username:password@host:port/database - Enter schema name (Optional)
- Enter the table name
- Provide the connection string in the following format:
- Pinecone:
- Enter your Pinecone API key
- Provide the Index name
- Pgvector:
- Link your embedding model : Provide information about the specific model here. Please pay attention that to achieve this successfully, you must use the same embedding model in SWE that you used to store the data.
Using the SDK
You can find the complete creation flow of the "AI Assistant Retrieval" application here. This SDK code snippet pertains to the creation of the VectorDB context within this flow.
PGVector VectorDB
from superwise_api.models.tool.tool import OpenAIEmbeddingModel, OpenAIEmbeddingModelVersion, ToolConfigPGVector
from superwise_api.models.context.context import ContextDef
vector_context = ContextDef(name="Context name", config=ToolConfigPGVector(
connection_string="Connection string",
table_name="Table name",
db_schema="Schema",
embedding_model=OpenAIEmbeddingModel(version=OpenAIEmbeddingModelVersion.TEXT_EMBEDDING_ADA_002, api_key="API KEY")
)
)
Pinecone VectorDB
from superwise_api.models.tool.tool import OpenAIEmbeddingModel, OpenAIEmbeddingModelVersion, ToolConfigPineconeVectorDB
from superwise_api.models.context.context import ContextDef
vector_context =ContextDef(name="", config=ToolConfigPineconeVectorDB(
api_key="pinecone api key",
index_name="test",
embedding_model=OpenAIEmbeddingModel(version=OpenAIEmbeddingModelVersion.TEXT_EMBEDDING_ADA_002, api_key="Open AI Key")
)
)
Updated 3 months ago