Calculate Drift metrics
Drift refers to the change in data distribution or model performance over time or across different datasets. Monitoring drift is essential in machine learning operations (MLOps) to ensure that a model’s assumptions about the data remain valid. Detecting drift early helps maintain model accuracy and reliability.
SUPERWISE® offers a flexible query builder that allows you to configure drift metrics based on your specific needs. To effectively monitor drift, follow these steps:
- Activate Compare Mode: Use compare mode to set up the two distributions you wish to analyze for drift.
- Create Distribution Queries: Formulate two distribution queries that you want to compare. Each query should capture the relevant data distributions you are interested in monitoring.
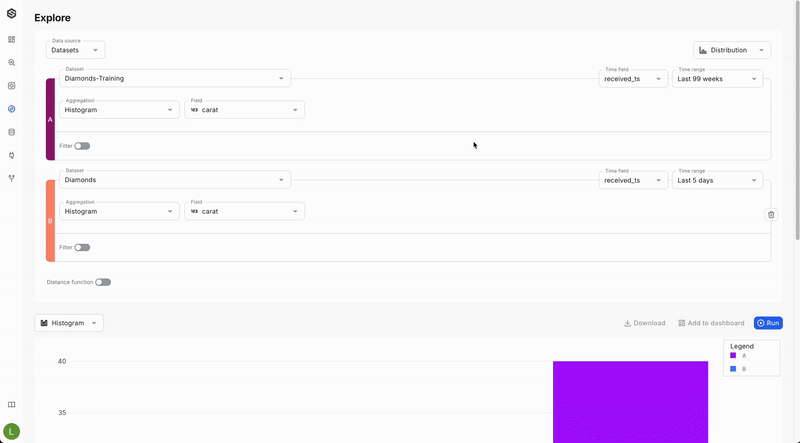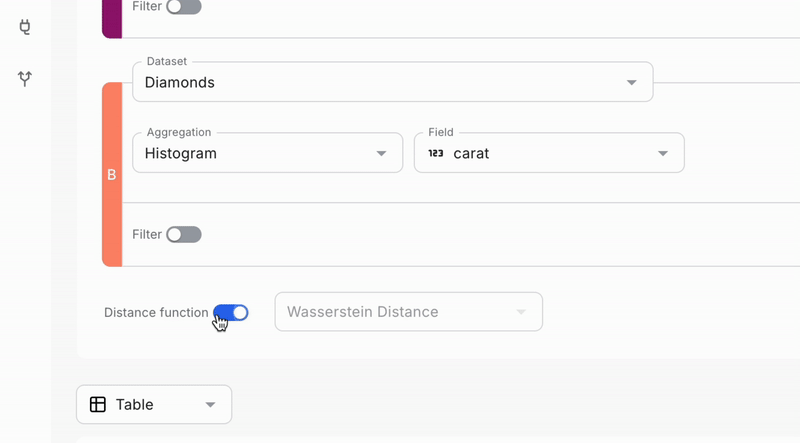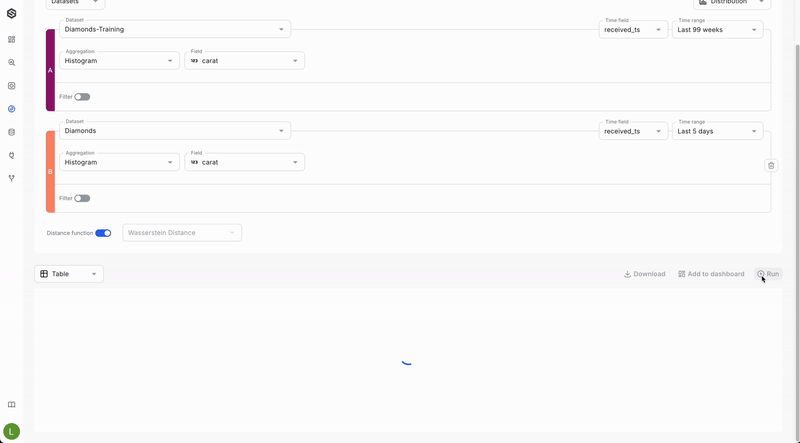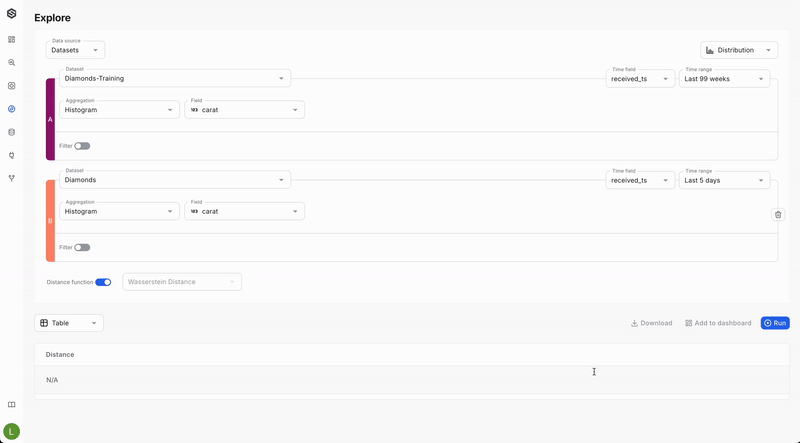
- Select a Drift Function: Choose your preferred function for calculating drift:
- Jensen–Shannon divergence: Recommended for comparing distributions of categorical values.
- Wasserstein Distance: Recommended for comparing distributions of numeric values.
Pay attention!
- The compare function can only be applied to two fields of the same type (e.g., numbers, strings, etc.).
- To create a meaningful drift function, perform the compare operation on the same field either within the same dataset or across different datasets
Updated 22 days ago